Upload Your Data
Begin a new schema matching task by uploading your dataset files.
1. Start a New Matching Task 🔄
To begin, click the “New Matching Task” button located on the far right of the navigation bar. This will open the upload interface.
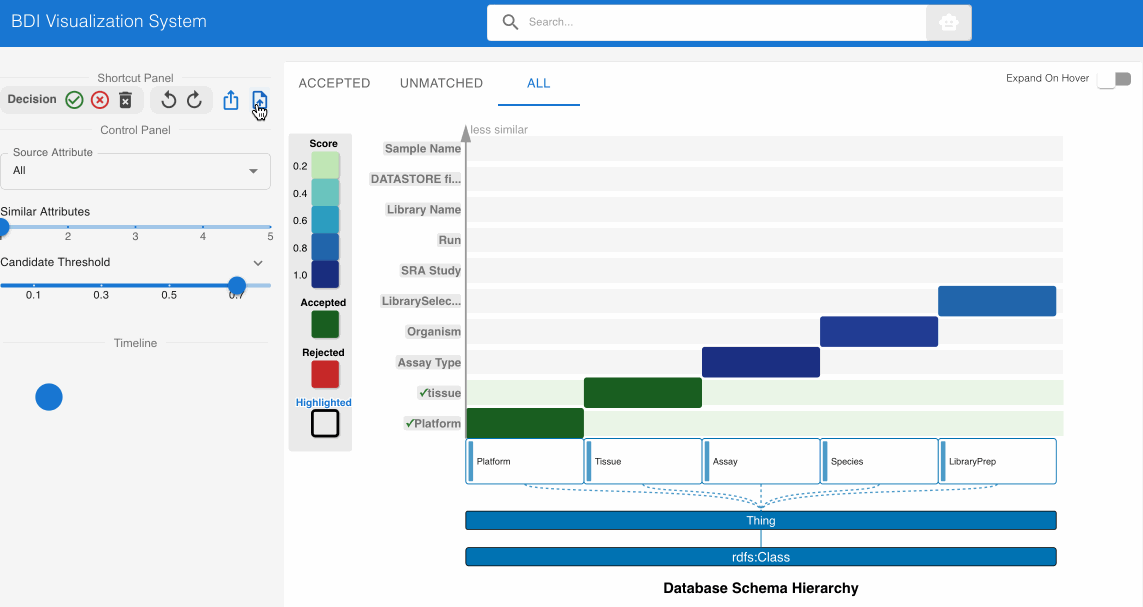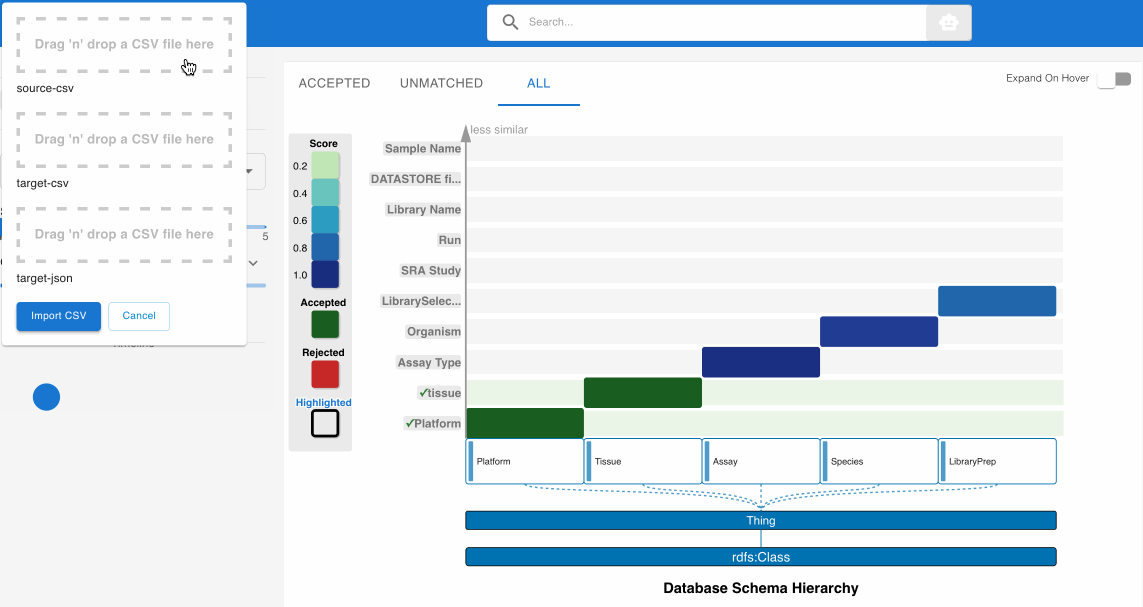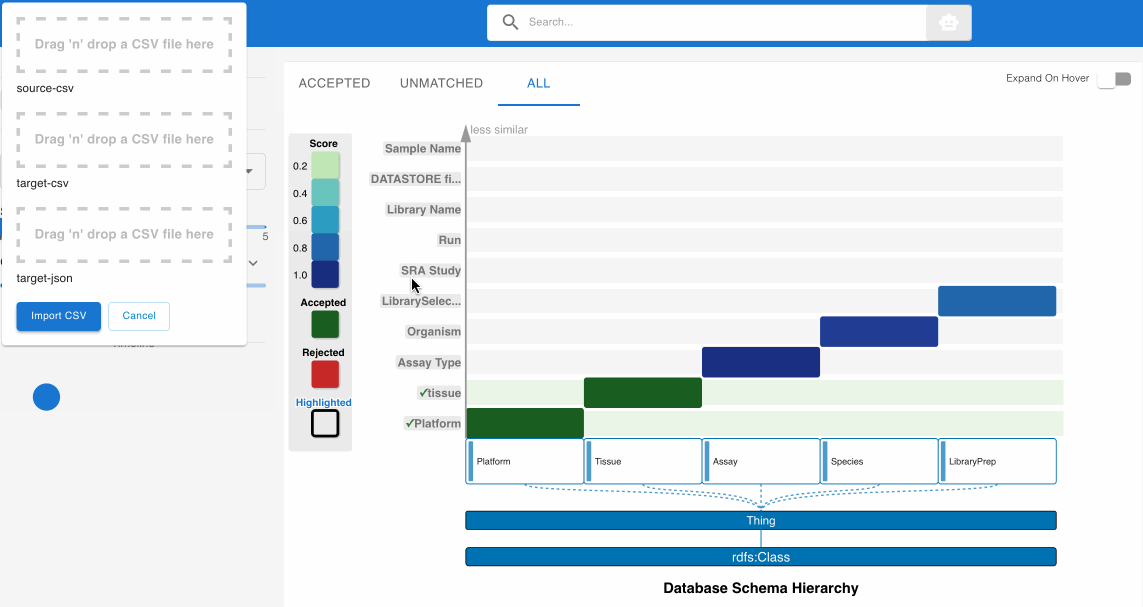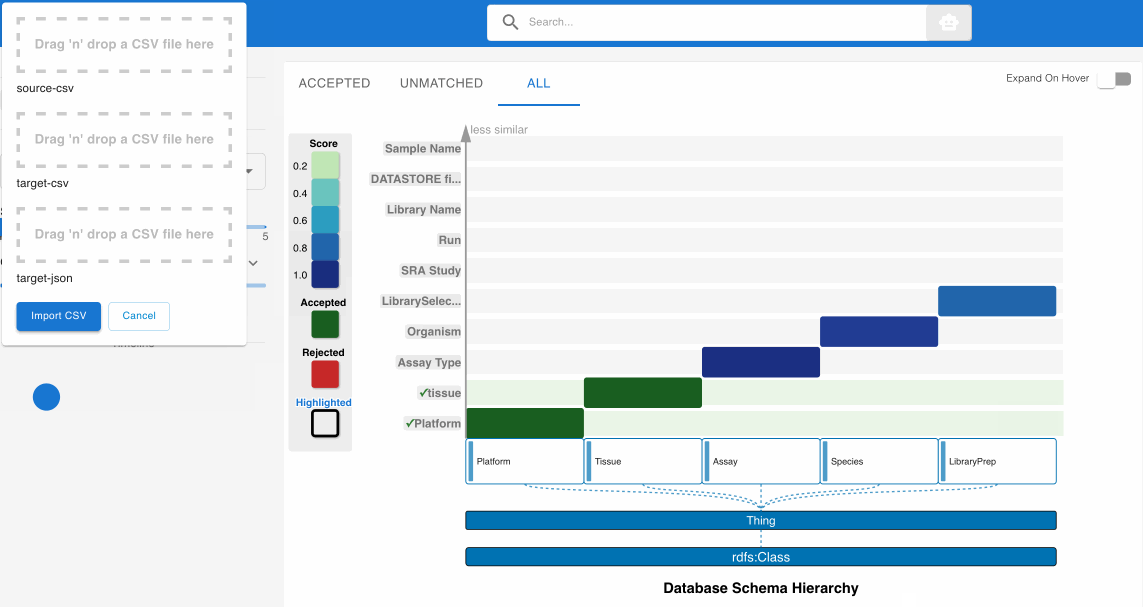
The interface presents three drop zones:
- Source CSV File – Your input dataset
- Target CSV File – The standardized reference dataset
- Target Schema JSON File – Metadata for interpreting the reference schema
These files are essential for initiating schema matching and visual comparison.
2. Upload Required Files 📂
A. Source CSV File (Required)
Upload a .csv file containing your unstructured or raw biomedical dataset. This will be used as the basis for matching.
Example:
| Case_ID | Gender | Ethnicity_Self_Identify | Path_Stage_Reg_Lymph_Nodes_pN |
|---|---|---|---|
| C1234 | Male | Asian | pN1 |
| C5678 | Female | White | pN2 |
| C1111 | Unknown | Unknown | pNX |
B. Target CSV File (Optional)
If omitted, the system will default to the GDC v3.3.0 schema.
Upload a .csv file that reflects the reference or gold-standard biomedical dataset (e.g., GDC, PDC).
Example:
| submitter_id | gender | race | ajcc_pathologic_n |
|---|---|---|---|
| T001 | Male | Asian | N1 |
| T002 | Female | White | N2 |
C. Target Schema JSON File (Optional)
If omitted, the system will use the GDC v3.3.0 schema definition.
Upload a .json file that defines metadata and attributes for the target schema.
Example:
{
"age_at_index": {
"column_name": "age_at_index",
"category": "clinical",
"node": "demographic",
"type": "integer",
"description": "The patient's age (in years) on the reference or anchor date used during date obfuscation.",
"minimum": 0
},
"education_level": {
"column_name": "education_level",
"category": "clinical",
"node": "demographic",
"type": "enum",
"description": "The years of schooling completed in graded public, private, or parochial schools, and in colleges, universities, or professional schools.",
"enum": [
"College Degree",
"High School Graduate or GED",
"Professional or Graduate Degree",
"Some High School or Less",
"Vocational College or Some College",
"Unknown",
"Not Reported"
]
}
}
3. Launch the Matching Task 🚀
Once all necessary files are uploaded, click the “Import CSV” button to start processing.
The system will:
- Analyze your source data in relation to the reference schema
- Generate schema alignment recommendations
- Display a loading indicator while processing is in progress
This step may take several minutes depending on the size of your dataset.
What’s Next? 🚀
After the task is launched, you will be redirected to the schema matching workspace where you can:
- Review alignment suggestions
- Accept or reject proposed matches
- Explore value mappings and distributions interactively